
How to fork ruoyi-vue-pro
To deploy a Springboot web framework, whatever development or production, and whatever single or distributed entity, ruoyi-vue-pro is a good project
But the stronger, the more complex. This post is the annotation for this project, by my personer opinion
Table of Contents
Tip: The most really important TECH cores, like design and architecture, they all service for BUSINESS.
NO BEST, ONLY BETTER.
I. ARCHITECTURE PRINCIPLE
The Unix philosophy is documented by Doug McIlroy[1] in the Bell System Technical Journal from 1978:
- Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new "features".
- Expect the output of every program to become the input to another, as yet unknown, program. Don't clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don't insist on interactive input.
- Design and build software, even operating systems, to be tried early, ideally within weeks. Don't hesitate to throw away the clumsy parts and rebuild them.
- Use tools in preference to unskilled help to lighten a programming task, even if you have to detour to build the tools and expect to throw some of them out after you've finished using them.
It was later summarized by Peter H. Salus in A Quarter-Century of Unix (1994): - Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams, because that is a universal interface.
In their Unix paper of 1974, Ritchie and Thompson quote the following design considerations: - Make it easy to write, test, and run programs.
- Interactive use instead of batch processing.
- Economy and elegance of design due to size constraints ("salvation through suffering").
- Self-supporting system: all Unix software is maintained under Unix.
So far, Mar 25, 2025
-
Reading the docs of ruoyi-vue-pro is the best way
-
如果团队比较小, 达不到上百人, 那么就不拆服务直接单体运行, 掌握设计的"度", 非常重要!!!
除非有动态扩缩,不同的模块由不同的团队单独维护,或者模块单独卖之类的需求,否则拆服务弊大于利 -
单仓多项目,大厂很多项目也在用这种方式. 有些人说会发展为分布式单体的,是对maven打包不大熟吧。运维角度来看,单仓和多仓git管理的打包产物都一样的,只是管理方式不一样
有些"伪微服务"项目,想跑起来就得clone一堆仓库,动不动出问题就是某个仓库更新了而关联模块的仓库没更新……
-
另外, git自带子模块, 建一个总的仓库, 各个服务作为子模块版本各自管理, 也是一种兼容方案
-
尽管代码中有DO, 但并不采用DDD(领域驱动设计)!!!
-
不使用RESTful style, 因为RESTful仍然有表达不明确的业务场景, 仍然需要使用传统"动词"来描述接口性质/意图, 且对团队要求较高, 一不小心就会破坏掉所谓的RESTful style
-
Write down all the details of requirement seriously
-
Draw UML(work flow), 设计初期, 后端概要/前端原型图 均不要太正式, 需要不断修正, 兼容前端表现(基于源码尽可能少量修改)与后端数据结构(尽可能解耦)的合理性
-
Designing the data structure and its relationship on the paper / iPad is the most important thing, with all detail fields
-
Record the SQL into the
./sql/mysql/and its System Manual SQL records. If need ER, export from MySQL, of course, my personal choice -
With its Infra code-auto-generation, most backend and frontend codes can be generated. Very helpful and so handy
II. BUSINESS DESIGN
-
mall只作为小程序B2C商城的载体
- 通过商品的SKU的barCode与ERP模块的产品建立联系
- 通过定时任务与ERP模块同步库存
-
ERP模块作为后台B2B的载体
-
产品倒卖
增加字段
supplier, 默认"0:本平台"增加字段
type, 默认成品- 管理mall的实体手办的库存(货源来自线下采购, 成品, 登记入库), 也不需要隐藏/保护上游产品码
- 管理mall的虚拟票券的库存(货源来自本平台, 成品, 生成入库)
-
产品生产
增加字段
supplier, 填写"(供应商ID):xx供应商"增加字段
type, 填写原料- 从上游采购回来的原料, 触发"生产"事件, 原料库存转化为成品库存, 隐藏/保护上游产品码
- 增加flow自动化流程链, 完整的源码ERP流程自动化完成
-
-
其它独立模块分别建立代码仓库, 单独维护
A. Controller
[TODO]: 继续描述源码在前后端结合时, 互相传递的参数以及显示字段的设计思路
1. Input validation
入参VO中的字段
- 基本遵从DO中的设计, 直接传输ID即可
- 因为前端加载页面时, 就已经通过多个接口的simple-list获取了各种下拉框的数据
- 提交时也就不需要
name之类的input字符串数据, 后台再通过字符串查询blablabla. 而是直接提交其ID即可, 后端直接用 - 本着创建与更新都采用同一套xxxSaveReqVO的原则
1 |
|
2. Output convertor
getPage
- 如果是产品名(等文字类描述), 无论是分页查询还是通过ID单体查询, 如果传输数字, 依靠前端二次轮询其对应的名称(等文字类描述), 则消耗太大, 所以需要后端通过Java stream复杂组装
- 如果是性别等通用字段, 输出也仍然是字典数值, 前端代码指定其字典类型, 通过字典接口从后端获取,
并转换为带有标签颜色的文字(成功 / 失败等)
Excel导出
1
2
3
4
5
6
7
8
9
@Schema(description = "管理后台 - 商品 SPU Response VO")
@Data
@ExcelIgnoreUnannotated
public class ProductSpuRespVO {
@Schema(description = "商品状态", requiredMode = Schema.RequiredMode.REQUIRED, example = "1")
@ExcelProperty(value = "商品状态", converter = DictConvert.class)
@DictFormat(DictTypeConstants.PRODUCT_SPU_STATUS) // 导出时也转换
private Integer status;
}
B. Service
- Service中, 只体现业务. 而需要CRUD的时候, 调用Mapper的方法
- service中的数据流转, 视情况而定, VO / DTO / DO 均可以
- SQL事务, 需要做好规划
- 通用事务方法的抽象
- 哪里添加事务注解
- 获取数据时是否已经提交事务
- 事务的隔离与传播, 是否运用得当
- 事务调用的生命周期/context
基本遵循源码自动生成的代码, 在良好的数据结构设计的基础上, 很多问题都能迎刃而解. 需要额外定制的几个参考用例, 如后文
业务流主方法中, 尽量只描述几个清晰的动作, 通用大部分业务流程, 有差异的处理流程, 放在前置or后置的handler中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@Resource
private List<XxxModuleFunctionHandler> saleOrderHandlers;
@Override
@Transactional(rollbackFor = Exception.class)
public Long createSaleOrder(ErpSaleOrderSaveReqVO createReqVO) {
// 1.1 校验订单项的有效性
// 1.2 校验客户
// 1.3 校验结算账户
// 1.4 校验销售人员
// 1.5 生成订单号,并校验唯一性
// 1.6 计算价格
// 2.0 前置处理(定制化处理, 动脑思考)
saleOrderHandlers.forEach(handler -> handler.beforeCreate(customerDO, saleOrder));
// 3.1 插入订单
// 3.2 插入订单项
// 4.0 后置处理(定制化处理, 动脑思考)
saleOrderHandlers.forEach(handler -> handler.afterCreate(customerDO, saleOrder));
return saleOrder;
1. Transactional
这里不会讲原理, 只讲注意点, 设计思路, 详细文章见java-spring.md
事务传播: 业务设计好一点, 代码简约一点, 事务的传播的事情会遇到得很少
事务隔离: MySQL默认是Repeatable Read, 暂且不太需要在代码中显式注明
1 |
|
2. Job
Quartz
3. Third-part API
以下2种都是Spring官方推荐的, 都是对HttpClient的封装, 简化使用, 提高效率
- RestTemplate: Sync, -> RestClient
doc 1
2
3@Deprecated(since = "6.0", forRemoval = true) public void setReadTimeout(int timeout) {} - WebClient: Async, since Sping 5.0
4. ApplicationEvent Monitor
module-bpm模块中有用到, 拿来主义, 上游入库后"生产"出下游库存就依靠这个监听者观察客户定制的BOM原料是否满足, 满足即可生产 [TODO]:
C. DAO Mapper
曾经我是拒绝的
- JUST use MyBatisPLus maven and use default CRUD methods - REFUSE to use QueryWrapper, only use MyBatis' XML mapper - MybatisPlus的QueryWrapper越看越像Python SQLAlchemy这类ORM, 学习成本高, 且一旦语句优化不得当, 会造成性能损失 - 按照MyBatis写XML更像原生SQL, 熟练运用SQL是一件愉快的事情
真香打脸
- Mapper中, 做统一抽象, 例如selectPage, selectByMobile... 而不是直接暴露selectOne selectList - 需要控制mapper中的SQL join(如下文) - 复杂业务都放在service中解耦, 周边模块的数据单独查询, 在Java内存中运用stream各种工具进行拼接
众多原因, 在符合各自需求的前提下, 适当取舍. 目前(May 27, 2025)的需求下, 引用如下作为主要概括还算是合适的:
Tip:不建议执行三张表以上的多表联合查询 对数据量不大的应用来说,多表联合查询开发高效,但是多表联合查询在表数据量大,并且没有索引的时候,如果进行笛卡儿积,那数据量会非常大,sql执行效率会非常低 多次单表查询在service层进行合并好处: 1、缓存效率更高, 许多应用程序可以方便地缓存单表查询对应的结果对象。如果关联中的某个表发生了变化,那么就无法使用查询缓存了,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。 2、多表信息联合的列表页面分页显示,只需要显示一部分的数据,如果是多表联合查询那要把所有数据联结查出来再执行limit,如果是多次单表查询,先对单表进行筛选,先执行limit再与其余表去关联,数据量会大大减小 3、如果数据库没有进行读写分离(主从备份),在并发量高的时候,由于写表会加排他锁,把多表联合查询改成单表查询后锁的粒度变小,减少了锁的竞争 4、在数据量变大之后,普遍会采用分库分表的方法来缓解数据库的压力,采用单表查询比多表联合查询更容易进行分库,不需要对sql语句进行大量的修改,更易扩展.分库分表的中间件一般对跨库join都支持不好 5、查询本身效率也可能会有所提升。查询 id 集的时候,使用 IN()代替关联查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的关联要更高效。 6、业务高速增长时,数据库作为最底层,最容易遇到瓶颈,单机数据库计算资源很贵,数据库同时要服务写和读,都需要消耗CPU,为了能让数据库的吞吐变得更高, 而业务又不在乎那几百微妙到毫秒级的延时差距,业务会把更多计算放到service层做,毕竟计算资源很好水平扩展,数据库很难啊,这是一种重业务,轻DB的架构 7、可以减少冗余记录的查询,在应用层做关联查询,意味着对于某条记录应用只需要查询一次,而在数据库中做关联查询,则可能需要重复地访问一部分数据。 更进一步,这样做相当于在应用中实现了哈希关联,而不是使用 MySQL 的嵌套循环关联。某些场景哈希关联的效率要高很多。 多次单表查询在service层进行合并缺点: 1、需要进行多次的数据库连接 2、代码更复杂 总结: 个人觉得还是做多次单表查询更好,更易扩展,当然数据量不大时,直接联合查询开发更方便
Multiple DB Settings
-
application.yml中设置PageHelper的 helperDialect, 兼容"mysql"和"sqlserver"两种数据库的语法
-
使用多数据源时, 配置PageHelper时要注意(只有在使用application.yml格式的配置文件时会有问题):
因为如果驼峰被自动转译为横线分隔符, 会导致PageHelper切换多数据源时失效... pagehelper: autoRuntimeDialect: true # 此处的配置项是驼峰, 不是IDEA自动提示的`auto-runtime-dialect: true` ...
D. CompletableFuture
| 场景 | 是否 completeExceptionally |
是否 return false |
推荐策略 |
|---|---|---|---|
| 🟥 严重错误,流程必须终止(如数据缺失、关键服务不可用) | ✅ 是 | ✅ 是 | 抛异常、日志、告警、主线程感知失败 |
| 🟧 次要异常,但允许流程继续(如第三方接口调用失败) | ❌ 否 | ❌ 否 | 写补偿任务,流程照常继续 |
| 🟨 需要人工介入或延后执行(如库存不足) | ❌ 否 | ✅ 是 | 挂起流程,等待外部回调 resume |
| 🟩 正常成功 | ❌ 否 | ❌ 否 | 正常流程链推进 |
III. TESTING
TODO: 2025年争取实现, 不再简单调用JetBrains的HTTP client, 而是使用UnitTest进行用例覆盖
不讲具体JavaUnitTest, 而是源码如何设置测试环境
IV. OPERATION
运营, 软文推广, 运维, 部署, 自动化测试, 自动化接口文档等
CI
TODO
API Document
- Swagger UI category, description and list
- With session token
Deployment
No best, only better! We DON’T want to use Docker.
最新的决策(Mar 25, 2025): 兄弟公司的相似业务, 采用复制型部署, 向产品商业部署方向转型, 后续考虑自动远程升级+离线手动升级策略
个人开发
- 前端:
- 使用
.env.local配置文件, 指向http://127.0.0.1:48080 - 调试命令
npm run dev
- 使用
- 后端:
- 使用
application-local.yaml配置文件, 数据源指向localhost - IDE调试即可
- 使用
开发互联网联调
- 前端:
- 使用
.env.dev配置文件, 后端地址指向https://mall.xxx.com - 调试命令
npm run dev-server - 打包命令
npm run build:dev
- 使用
- 后端:
- 使用
application-dev.yaml配置文件, 数据源指向开发数据库 - 云服务配置
https://mall.dev.xxx.com, 域名解析, 开放端口及备案, SSL证书 - 使用
screen运行在开发服务器即可, 供前后端远程调试用 - Nginx采用服务器局域网IP访问的方式, 目前不太需要采用独立域名的方式
- 使用
生产环境
- 前端:
- 使用
.env.prod配置文件, 后端地址指向http://192.168.1.100 - 打包命令
npm run build:prod
- 使用
- 后端:
- 使用
application-prod.yaml配置文件, 数据源大都指向服务器本地 - 云服务配置
https://mall.xxx.com, 域名解析, 开放端口及备案, SSL证书; 或者内网IP地址 - 使用Ubuntu系统服务(仍然暂不使用Docker)
- Nginx采用服务器局域网IP访问的方式
- 使用
- external
- internal
1 |
|
V. COMMON CORE
理解源码的核心设计思路, 具体技术知识见java-spring.md
A. Exception
B. Log
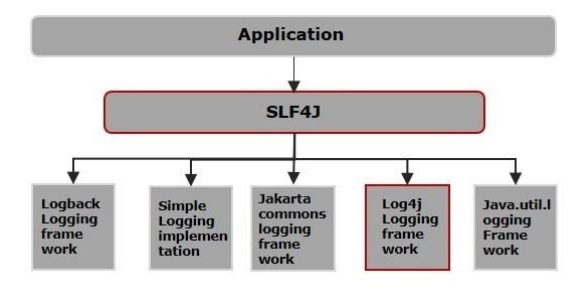
slf4j.Logger and log4j.Logger
Comparison SLF4J and Log4j
Unlike log4j, SLF4J (Simple Logging Facade for Java) is not an implementation of logging framework, it is an abstraction for all those logging frameworks in Java similar to log4J. Therefore, you cannot compare both. However, it is always difficult to prefer one between the two.
C. Cache
Redis cache
MyBatis Cache
MyBatis的一级缓存和二级缓存, 都存在可能脏读的情况, 所以一般惯用Redis做缓存 引入Redis后只需要将MyBatis配置文件中Cache 的类型定义为RedisCache
D. StreamUtils
用得越来越多了, 有时间的话, 需要系统性学习一下
convertSet
convertMultiMap
convertMap
MapUtils.findAndThen
E.PayLock
F.Tenant
MyBatisPlusX中有AoP控制
Mar 24, 2025, 源码采用的是单数据库, 表单字段 隔离的租户机制
- 隔离效果, 始终觉得有隐患, 弃用
- 但将来会可能面对多数据源事务, 到时再说XD
宁可采用:兄弟公司相似业务+隔离复制部署+通用部分远程升级 的机制
另外, 断面自动测量系统直接在application.yaml中yudao.tenant.enable:false关闭了租户功能
G. Connection Pool
Druid or Hikari -> PearAdminPro用的是Hikari, 也是Springboot官方选用的 Druid是淘宝选用的, 高并发的情况会适用一些
H. Security
只记录配置, 新的, 技术链接看java-spring.md
1. 免登录改哪里
在.yaml中有设置免登录路径
2. 登录方式有哪些
3. permission权限设置, 部门数据隔离
PermissionServiceImpl
VI. FRONTEND
此处仅记录前端的一些本地化的修改, 以免忘记
A. 设计思路理解
对于前端的理解为: 更多地通过多接口异步从后端获取获取多种数据, 组装成可读的文字页面数据, 不是一个接口从后端获取N多组装后的文字页面数据
既降低了后端组装数据的复杂度, 也利于前后端数据解耦
Enumerator只记录固化的业务代码锚定点, 不用于页面颜色标签的体现
前端采用DICT_TYPE_工具通过字典接口从后端获取该数值所对应的文字颜色标签, 用于页面友好度体现
需要额外跳转的, 使用Router配置
B. 菜单配置
在Web上配置菜单
- 路由地址:
user, 与源码前端代码的代码文件夹名称一致 - 组件地址:
system/user/index, 与代码同路径index.vue一致 - 组件名称:
SystemUser, 与index.vue中defineOptions({ name: 'SystemUser' })一致 - 权限名称:
system:user:list, 与index.vue中的中的v-hasPermi="system:user:list"一致
C. 本地化修改
新源码clone下来后, 按照目录顺序修改如下内容:
- public
- favicon.ico
- logo.gif
- src
- api
- erp
- sale, 临时增加了订单接口
- measure, 增加自定义的接口
- erp
- assets
- imgs
- avatar.gif, 替换
- logo.png, 替换
- svgs
- login-box-bg.svg, 替换
- imgs
- layout
- components
- UserInfo
- src
- UserInfo.vue, 取消web外圈 用户中心 鼠标悬停时的"项目文档"
- src
- UserInfo
- components
- locales
- en.ts, 修改英文相关的
- zh-CN.ts, 修改中文相关的
- jp?.ts, 修改日文相关的
- router
- modules
- remaining.ts, 按规则增加ERP模块中下游客户的销售策略, 以及Measure模块的测量结果 的路由设置
- modules
- store
- modules
- locales.ts, 增加多语言下拉选项
- modules
- utils
- constants.ts, 增加Measure相关的代码枚举
- dict.ts, 增加Measure相关的字典
- views
- Home
- Index.vue, 首页文字修改
- Login
- Login.vue, 修改登录页, 取消了LoginForm
- components
- LoginForm.vue, 修改登录选项等
- measure, 增加Measure模块
- erp
- 临时记录erp修改的订单页
- Home
- api
- types
- global.d.ts, 增加
type LocaleType = 'zh-CN' | 'en'日语支持
- global.d.ts, 增加
- .env, 修改标题, 租户, 用户, 密码, 文档开关
- .env.dev, local, prod 按需修改即可
- index.html, 修改文字等
VII. APPENDIX
摘抄自网络, 不一定合理, 仅保存一些文字, 以便以后少写一些文字
缩写信息
- DAO: Data Access Object, 数据访问层
- PO: Persistant Object, 持久层对象. 类似数据库内的一条记录
- DO: Domain Object, 领域对象
- DTO: Data Transfer Object, 通常在OpenApi返回的对象中使用DTO, 忠于表结构原始数值{“age”:40}
- BO: Business Object, 业务对象
- VO: Value Object, 表现对象 (如果需要, 则转换为具体表现的内容, 例如{“age”:40, “desc”:“不惑之年”})
- POJO: Plain Old Java Object, 是PO/DO/DTO/BO/VO的统称
命名规范
- Service/DAO层方法命名规约
- 获取单个对象的方法用get做前缀
获取多个对象的方法用list做前缀- 获取统计值的方法用count做前缀
- 插入的方法用save/insert做前缀
- 删除的方法用remove/delete做前缀
- 修改的方法用edit/update做前缀
领域模型命名规约- 数据对象: xxxDO, xxx即表名
- 数据传输对象: xxxDTO, xxx即业务领域相关的名称
- 展示对象: xxxVO, xxx一般为网页名称
- POJO是DO/DTO/BO/VO的统称, 禁止命名成xxxPOJO
